|
Email: hbxuan@tju.edu.cn Google Scholar Github I am a graduate student of College of Intelligence and Computing, Tinanjin University in fall, 2021 and under the supervision of Prof. Kun Li. My research focuses on digital human, human reconstruction and human scene interaction. |

|
|
|

|
Haibiao Xuan, Xiongzheng Li, Jinsong Zhang, Hongwen Zhang, Yebin Liu, and Kun Li IEEE International Conference on Computer Vision (ICCV), Poster, 2023. [Project] [PDF] [Code] [BibTeX] We propose a novel relationship reasoning-based generative approach, Narrator, for naturally controllable generation given a 3D scene and a textual description. |
|
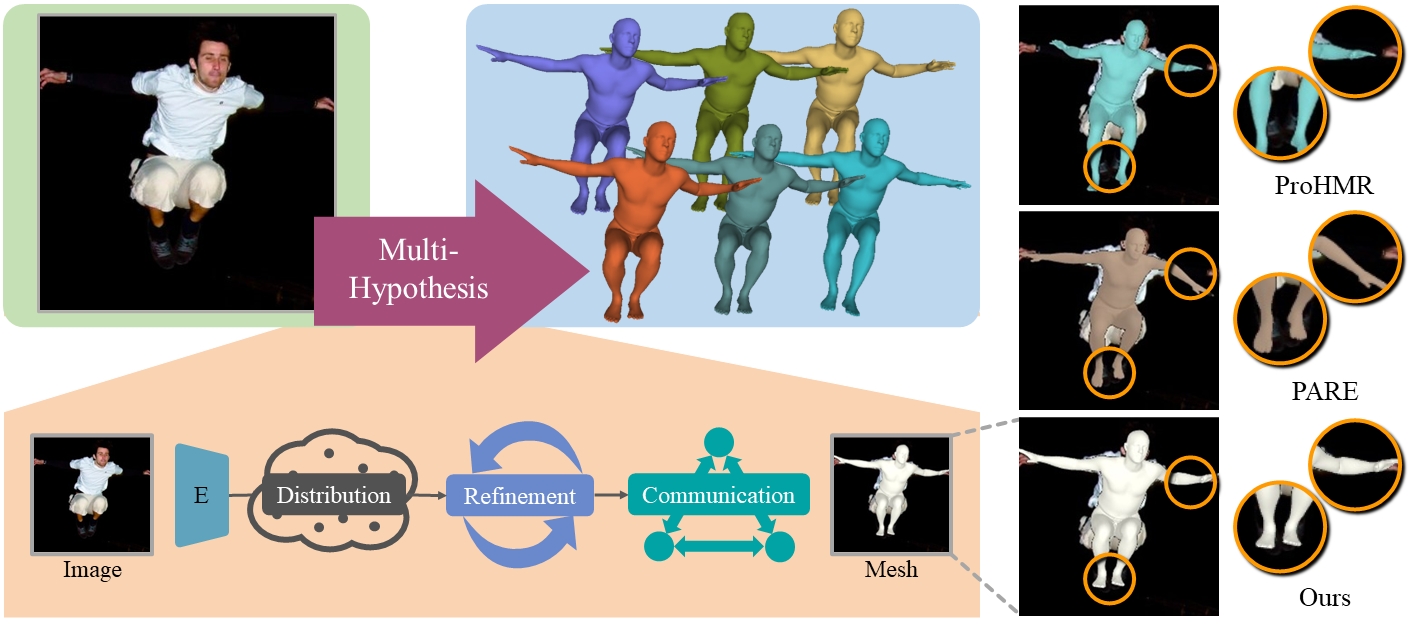
Haibiao Xuan, Jinsong Zhang, Yu-Kun Lai, and Kun Li CACAI 2022 (Oral) & CAAI TRIT 2023. [Project] [PDF] [Code] [BibTeX] We embrace the ambiguity of the reconstruction and propose a multi-hypothesis approach, MH-HMR, to efficiently model the multi-hypothesis representation and build strong relationships among the hypothetical features. |
|
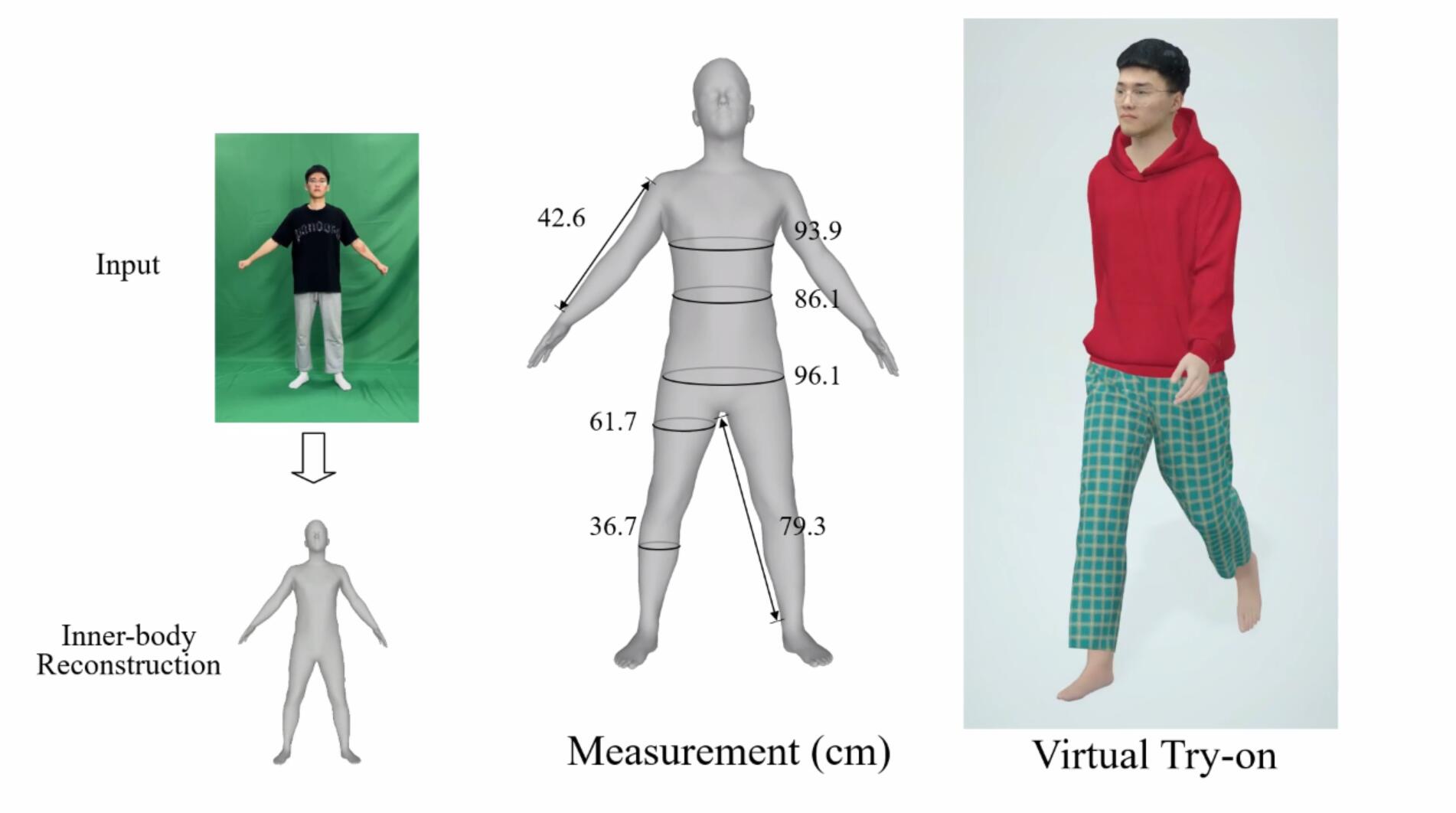
Xiongzheng Li, Jing Huang, Jinsong Zhang, Xiaokun Sun, Haibiao Xuan, Yu-Kun Lai, Yingdi Xie, Jingyu Yang and Kun Li IEEE Transactions on Visualization and Computer Graphics (TVCG), 2022. [Project] [PDF] [Code] [BibTeX] We propose the first method to allow everyone to easily reconstruct their own 3D inner-body under daily clothing from a self-captured video with the mean reconstruction error of 0.73cm within 15s. |